
Papers
|
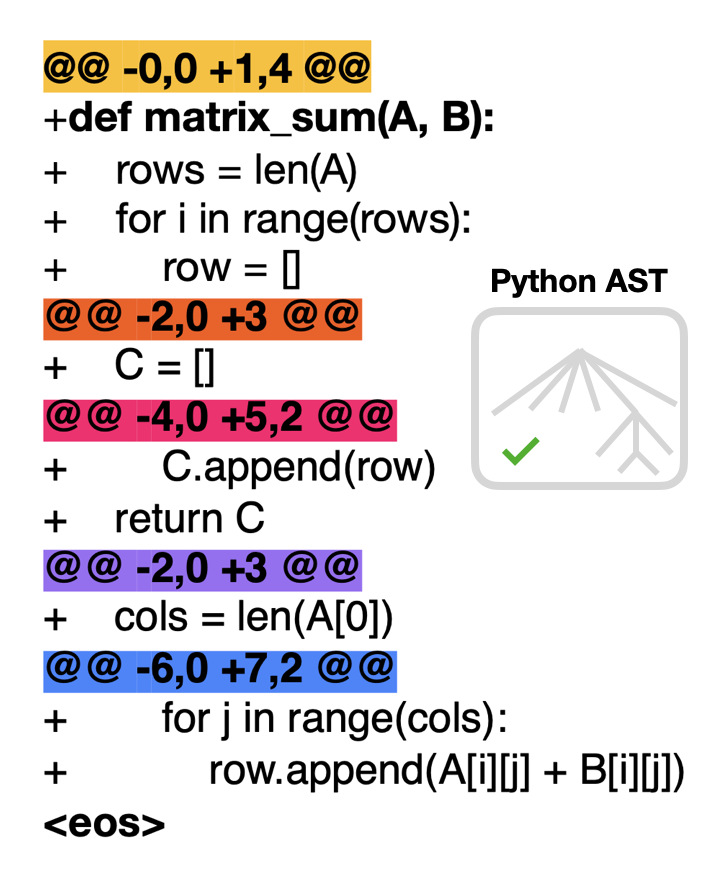
Training Language Models on Synthetic Edit Sequences Improves Code SynthesisUlyana Piterbarg, Lerrel Pinto, Rob Fergus NENLP (Outstanding Paper Award), ICLR, 2025 arXiv / project page / code / The key to solving a hard problem often lies in knowing how to decompose it into sub-problems. We show that training autoregressive LMs to synthesize code edit-by-edit improves the slope of test-time scaling laws on benchmarks like HumanEval, MBPP, and CodeContests. Our approach introduces an algorithm for generating synthetic code edit data at scale: LintSeq. Edits sampled with this algorithm reflect the semantics & syntax of their programming language. |

|
BALROG: Benchmarking Agentic LLM and VLM Reasoning On GamesDavide Paglieri, Bartłomiej Cupiał*, Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuciński, Lerrel Pinto Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, Tim Rocktäschel ICLR, 2025 arXiv / project page / code / We introduce BALROG, a benchmark designed to assess the agentic capabilities of LLMs and VLMs through a set of increasingly challenging games. Frontier models like Claude 3.5 Sonnet and GPT-4o achieve <2% progress on the hardest game in BALROG, the notorious roguelike dungeoncrawler NetHack. |
|
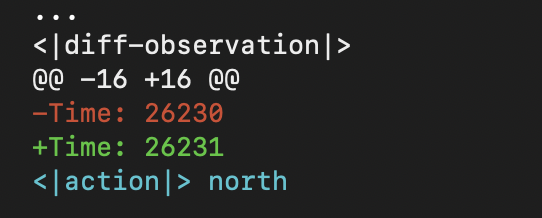
diff History for Neural Language AgentsUlyana Piterbarg, Lerrel Pinto, Rob Fergus ICML, 2024 arXiv / project page / code / We propose that long-context LMs for decision-making, interaction, and/or world-modeling be trained on demonstration data consisting of textual observation deltas, or diff history. Diff history can be thought of as a textual analogue of optical flow. Using diff history, we show that even tiny LMs (~120M parameters) can be efficiently tuned into highly competitive and robust agents for hard decision-making settings like the video-game NetHack, where they match state-of-the-art despite being tuned on 1800x fewer data than prior work. |

|
NetHack is Hard to HackUlyana Piterbarg, Lerrel Pinto, Rob Fergus 37th Conference on Neural Information Processing Systems (NeurIPS), 2023 arXiv / project page / code / Neural policy learning methods struggle in long-horizon tasks, especially in open-ended environments with multi-modal observations, such as the popular dungeon-crawler game, NetHack. In the NeurIPS 2021 NetHack Challenge, symbolic agents outperformed neural approaches by over four times in median game score. In this paper, we delve into the reasons behind this performance gap and present an extensive study on neural policy learning for NetHack. Our investigations produce a state-of-the-art neural agent. However, we also demonstrate that scaling up supervised learning is insufficient to bridge the performance gap with the best symbolic models or even the top human players. |
|
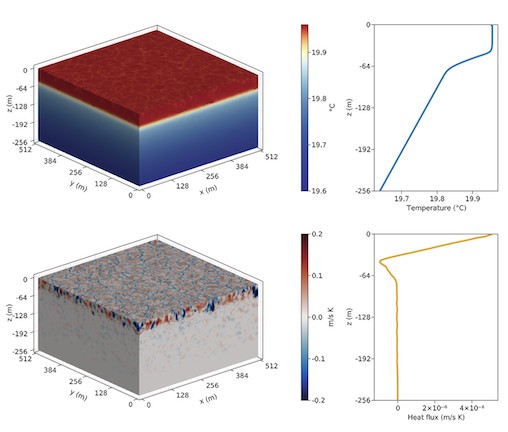
Capturing missing physics in climate model parameterizations using neural differential equationsAli Ramadhan, John C Marshall, Andre Nogueira Souza, Xin Kai Lee, Ulyana Piterbarg, Adeline Hillier, Gregory LeClaire Wagner, Christopher Rackauckas, Chris Hill, Jean-Michel Campin, Raffaele Ferrari Earth and Space Science Open Archive (ESSOAR), 2022 arXiv / code / We explore how neural differential equations (NDEs) may be trained on highly resolved fluid-dynamical models of unresolved scales providing an ideal framework for data-driven parameterizations in climate models. NDEs overcome some of the limitations of traditional neural networks (NNs) in fluid dynamical applications in that they can readily incorporate conservation laws and boundary conditions and are stable when integrated over time. We advocate a method that employs a “residual” approach, in which the NN is used to improve upon an existing parameterization through the representation of residual fluxes which are not captured by the base parameterization. |
|
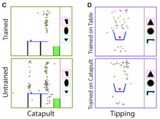
Abstract strategy learning underlies flexible transfer in physical problem solvingKelsey R. Allen, Kevin A. Smith, Ulyana Piterbarg, Robert Chen, Josh B. Tenenbaum CogSci, 2020 What do people learn when they repeatedly try to solve a set of related problems? In a set of three different exploratory physical problem solving experiments, participants consistently learn strategies rather than generically better world models. Our results suggested that people can make use of limited experience to learn abstract strategies that go beyond simple model-free policies and are instead object-oriented, adaptable, and can be parameterized by model-based variables such as weight. |
Unpublished Work

|
Biped Locomotion from Human Demonstrations with Motion Imitation via RLMIT 6.832: Underactuated Robotics (graduate) (2021-05-17)I experimented with reinforcement learning as a basis for learning bipedal locomotive skills from human demonstrations, using data from the CMU Motion Capture Database as the demonstration source and the NASA Valkyrie (R5) robot as the target system for motion imitation. This work draws from Peng at al. 2020 and Xie et al. 2019. |

|
Experiments with Quasi-Geostrophic FlowsMIT Ferrari Lab (2021-01-10)Under the supervision of Andre N. Souza, I experimented with turbulent regimes of quasigeostrophic flows, numerically approximated using Julia. |

|
A Bayesian Approach to Modeling Infection-Based Social Distancing in the SARS-CoV-2 PandemicMIT IDS.147/15.077: Statistical Learning and Data Mining (graduate) (2020-05-20)This project revolves around a simple extension of the classical SIR compartmental model of disease transmission that parameterizes infection-based social distancing policy i.e., the feedback SIR (fSIR) model imagined by Dr. Elisa Franco. I fit this model via the probabilistic programming package PyMC3 against true statistics of infection from four countries with sharply-contrasting responses to the pandemic, yielding posteriors that made it possible to perform a rough numerical comparison of policy-efficacy. |

|
Exploring strategy learning in the “Tools Environment”MIT 9.66/9.660/6.804: Computational Cognitive Science (2018-12-10)I worked with Kevin A. Smith and Kelsey R. Allen to design and to run a preliminary study testing the Virtual Tools Game as a testbed for behavioral experiments studying abstract strategy learning in humans. I also designed a hierarchical Bayesian mixture model to identify the abstract strategies learned by study participants directly from data. |

|
Investigating Option-Conditional Value Prediction in Reinforcement LearningEPFL Life Sciences Summer Research Program Colloquium (2018-08-15)Supervised by Johanni Brea and Wulfram Gerstner, I investigated the efficacy of option-conditional value prediction in reinforcement learning (RL) by adapting the Value Prediction Network for tabular environments as well as by implementing the algorithm as in Oh et al.’s original paper, using a combination of temporal-difference search (TD search) and n-step Q-learning for training. |

|
Anamorphic Entrance Scupture PrototypeAMNH Exhibitions Department (2017-06-10)I co-designed the prototype of an anamorphic entrance sculpture to the American Museum of Natural History special exhibition “Our Senses: An Immersive Experience.” The final sculpture was included in the New York Times feature on the exhibition, “This Exhibition Will Help You Make Sense of Your Senses”. |