NetHack is an open-source, roguelike video game first released in 1987. The game is procedurally generated, features ASCII graphics, and is notoriously difficult to play. The source code is written inC.
In 2020, Küttler et al. released the NetHack Learning Environment (NLE), wrapping the video game into a reinforcement learning (RL) environment for ML/AI research. This environment was presented at NeurIPS 2020.
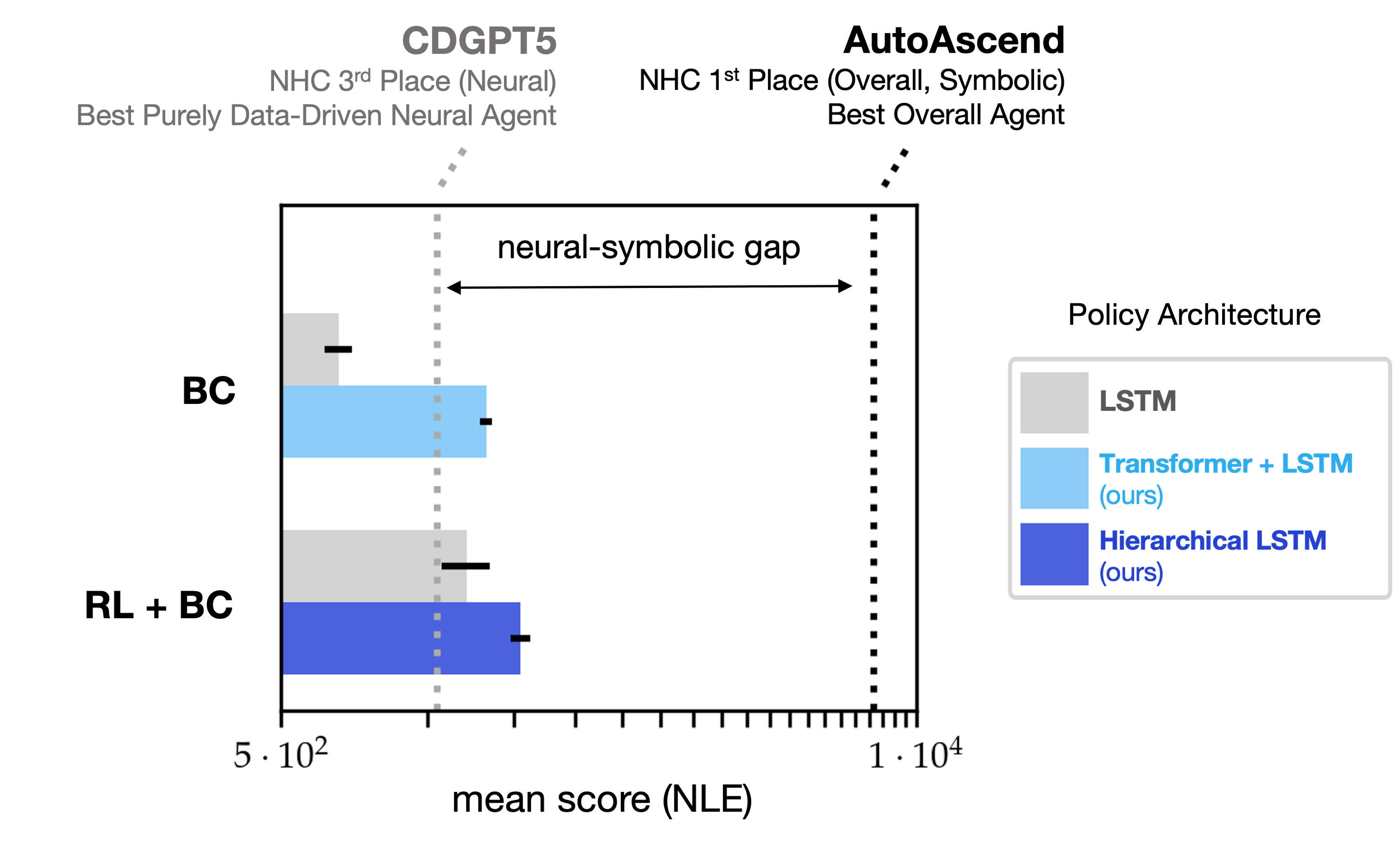
A year later at NeurIPS 2021, Hambro et al. organized a competition centered on NetHack, dubbed "The NetHack Challenge Competition" (NHC). This competition spurred AI researchers, machine learning enthusiasists, and members of the community at large into benchmarking and developing neural and symbolic methods inNLE. Symbolic methods beat out neural ones in average in-game score by a staggering margin, leaving purely data-driven neural policies in the dust (Figure 1).
You can read more about NetHack via the game homepage or by checking out the community-maintained NetHack Wiki.
♞ ⚔ ⚄ Hi Hack ⚀ ⚔ ♝
FAQs
1. NetHack remains unsolved.
2. Due to its procedurally generated nature, NetHack truly probes policy generalization. Each random seed of the game features a completely unique layout of dungeons, monster encounters, and items to gather.
3. NetHack is compiled inC, yielding blazingly fast simulation. Training neural policies inNLEwith RL remains tractable despite the high complexity of the game.
4. HiHack. Unlike other open-ended RL environments like Habitat, MineCraft, or AI2-Thor, the state-of-the-art (SOTA) artificial agent in NetHack is an open-source, hard-coded, symbolic, and hierarchical bot, which we "hack" to generate hierarchically labeled demonstration data. HiHack provides the community with a unique opportunity to explore the impact of ground-truth hierarchical behavioral priors on learning, in a data-unlimited setting.
HiHack contains 109,907 games and 3,244,729,367 keypresses (Table 1). After extraction tottyrec4.bz2files, the full dataset is99 GB.
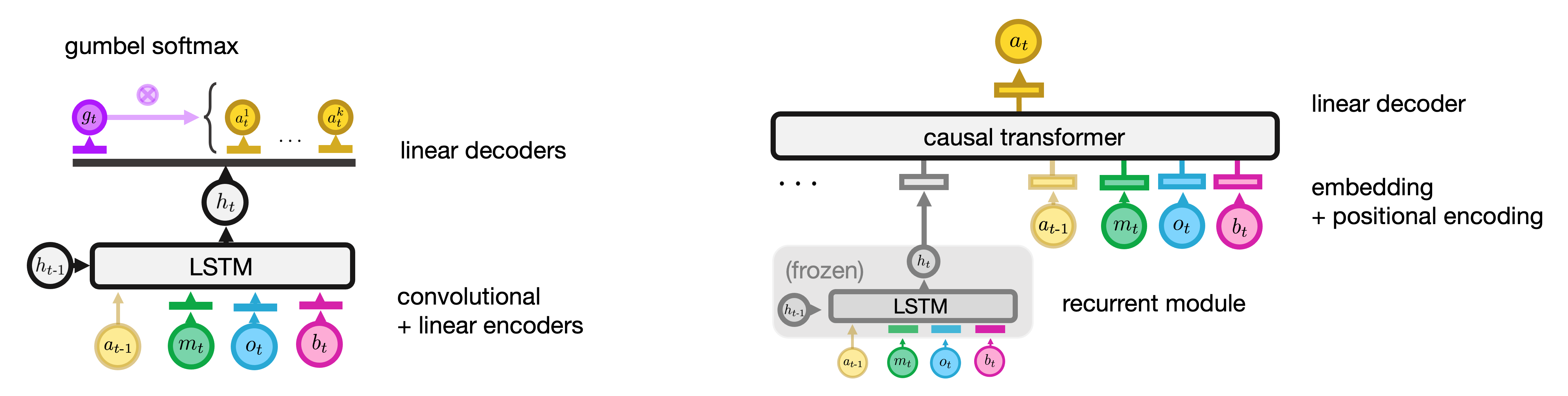
Despite its scale, neural policies trained on HiHack with imitation learning fail to match the bot inNLEscore, even when RL finetuning is thrown into the mix. In the purely offline regime, neural policy architectures based on LSTMs and even transformers (Figure 2) exhibit sub log-linear scaling inNLEscore with demonstration count (Piterbarg et al., 2023).
HiHack is saved in the ttyrec data format native to NetHack. 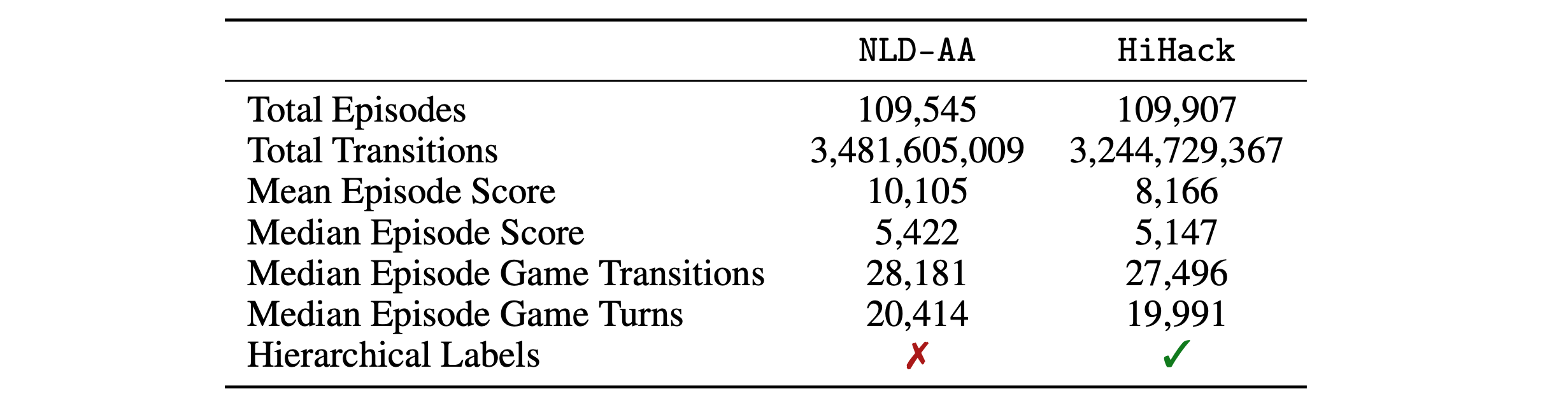
NLD-AA (Hambro et al., 2022).See Table 1 for a comparison of HiHack to theAutoAscendNetHack Learning Dataset (NLD-AA), the latter containing demonstrations with keypress labels only.
HiHack was generated through the introduction of explicit "strategy" tracking to theAutoAscendsource code and to thettyrecread/write code ofNLE. We open-source all code employed for data generation.
As of October 30, 2023, the SOTA for data-driven neural policies in NLE is set by agents trained on HiHack, both in the purely offline and offline + online settings (Piterbarg et al., 2023). See Table 2 below and our paper for more details.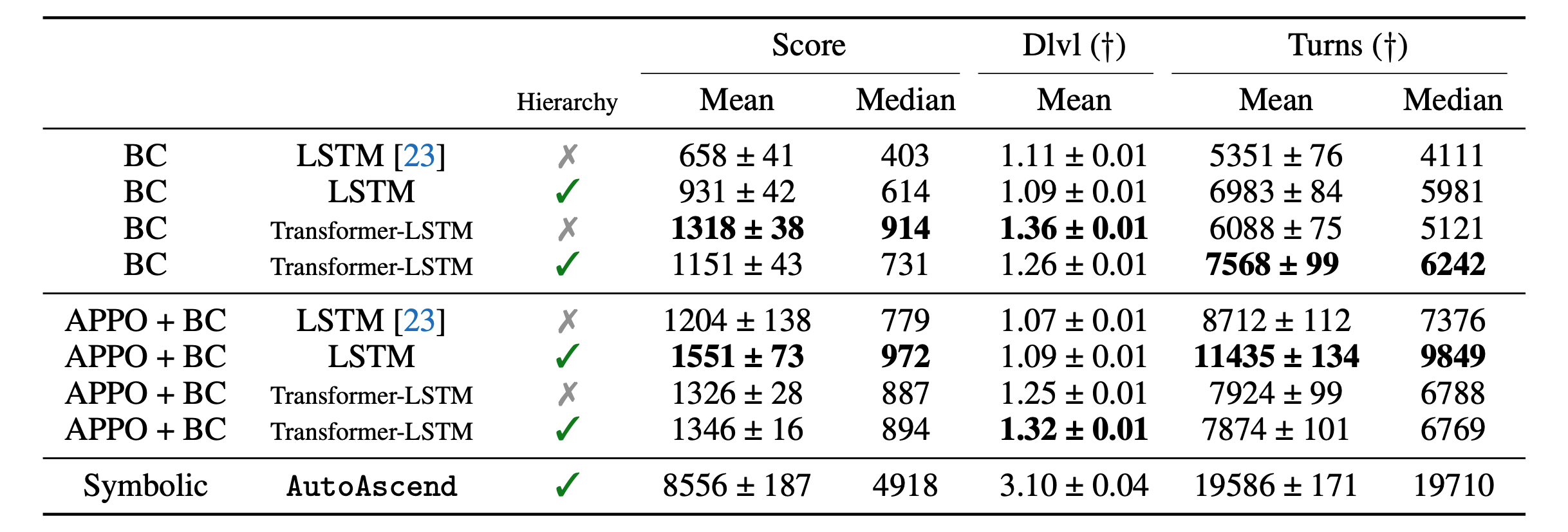
Please send any inqueries to up2021 -at- cims.nyu.edu . @misc{ piterbarg2023nethack,
title={ NetHack is Hard to Hack },
author={ Ulyana Piterbarg and Lerrel Pinto and Rob Fergus },
year={ 2023 },
eprint={ 2305.19240 },
archivePrefix={ arXiv },
primaryClass={ cs.LG }
}